上海昨天已经开始下大雪,今天早上起来,竟然积了挺厚的一层雪,虽然还没有银妆素裹的感觉,不过对于好几年没有下大雪的上海来说,已经够我兴奋一阵子了。我记得上次看到这么大的雪应该是在我初二的时候,也就是大概93,94年的样子。之后就没有过这么大的雪了。我今天特意带上了相机,一路上班,一路稍微拍些照片,留个纪念。谁知道下一次上海下这么大的雪是什么时候呢?随着全球气候变暖,上海这个南方城市能飘个雪花,下个雪子已经很不错了。
这是张江,我工作的地方。

路上的积雪其实不是很厚,但是走在上面滑溜溜的感觉真是久违了!路上看到有些女孩子很开心的滑着走路,看来年轻人的心情都差不多啊,呵呵。
走向张江软件园...路上的积雪已经被无数张江男,张江女踩化了。
以前短短的5分钟路,今天却格外的长。

2008年1月28日星期一
2008年第一场大雪
2008年1月26日星期六
C++基础知识:函数指针
本文总结了C++中函数指针的使用方法和使用场合
声明
函数指针在C语言中已经存在,顾名思义,这是一个指向函数的指针。其声明方式如下:
int (*fp)(int); // a pointer to function that takes an int and return an int
这是一个“指向带有一个int参数,返回int值的函数的指针”。这时候可以把为该指针这样赋值。
int foo(int);
fp = foo;
fp = &foo;
fp = 0;
可以用函数名直接赋值,也可以用显式的方式用地址符取函数地址,函数指针还可以赋值为0。这和其他指针是一样的。不过直接取地址的方式是没有必要的。编译器会帮你取地址。
调用
函数指针的调用有两种方式,显式(简化)调用和隐式调用。
int k = (*fp)(100);
k = fp(100);
这两种方式是一样的。但是后面一种显然更符合使用习惯,不过请记住,这只是一种简化。
使用
最常见的使用方式是回调函数。回调函数的意思是把函数指针告诉别的程序,由别的程序决定何时调用。比如windows编程常用的subclassing方式
LONG NewWindowProc(HWND,UINT,WPARAM,LPARAM); //申明了一个用来回调的函数。
SetWindowLongPtr(hWnd,DWLP_DLGPROC,NewWindowProc); // 设置了回调函数
// 当有信息过来的时候,windows 会调用NewWindowProc。
LONG NewWindowProc(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam)
{
// message processing logic.
}
回调函数一般在“当你不知道何时调用函数,但是知道函数该执行什么样的任务,返回什么样的结果的时候用”
再来一个例子,一个书店有两种方式付款,现金和信用卡,用户可以选择使用一种方式付款,为了让程序简便,可以使用函数指针:
extern bool PayByCash(double);
bool PayByCreditCard(double){...}
bool (*Pay)(double);
if( CustomerWantByCash )
Pay = PayByCash(amount); // amount is a double
else
Pay = PayByCreditCard(amount);
....// do some prepaid check and preparation
bool success = Pay();
如果想要把函数指针用在重载函数中,函数指针本身必须提供多个重载版本。解析规则和重载函数解析规则相同。比如:
还有一种常用的方式是把函数指针传递给另外一个函数,使得那个函数可以在它自己的函数体内调用我们传入的函数指针。比如设计一个sort函数,它接受三个参数,前面两个参数是两个相同类型的对象实例,最后一个参数需要一个函数来告诉它如何比较。我们这里不讨论具体实现,仅看看其声明方式:
bool PayByCash(double);
bool PayByCash();
bool (*Pay)(double);
Pay = PayByCash;
Pay(1000.0); // 调用的是第一个PayByCash; 因为类型一致
Pay(); // error!
void sort( T, T, fp);
这里的fp将是一个函数指针,指向一个函数接受sort的前面两个参数,然后返回一个int值,来表明两个T的逻辑上的大小。因此这样的函数可以声明为:
int compare( T , T )();
因此对应的函数指针为:
int (*fpc)(T,T)();
其类型为
int (*)(T,T)
因此sort函数的原型可以声明为:
void sort( T, T , int (*)(T,T) ) ;
使用typedef,提高可读性:
typedef int (*CH)(T,T);
void sort( T,T, CH );
提升难度
现在,我们来提升一下难度!假设我在首地址为0的地方有个子函数,我该如何去调用呢?让我们想一想!首先我们已经知道了函数指针的声明方式:
void (*fp)();
在C/C++中,知道了一个类型,那么它的类型转换符也就容易得到了。只要把声明中的变量和最后的分号去掉即可,再在外面用括号括起来,也就是:
(void (*)())
这就是一个指向没有返回值的函数的指针。
这时候,我们可以把0地址强制转换成函数指针了。也就是:
(void (*)())0 ---- (1)
这就是一个指针,把他看做void (*fp)()中的fp即可。想想我们如何调用fp指向的函数的?不就是fp()么?但是这里由于是强制转换的,因此不能用这种隐式方式,要使用显式调用方式,也就是(*fp)();
我们把上面的fp替换为开头的 (1)式,既得:
(*(void (*)())0)();
但是这种方式大家都会看着头痛,因此我们可以用typedef声明。
typedef void (*fp)()
(*(fp)0)();
2008年1月24日星期四
一等奖引发的混乱
我发誓这是最后一次写关于这次的一等奖了。主要是我实在忍不住要骂人了。
上次提到公司让我自己订票,然后他们找代理公司打钱。然后出票,把行程单发给我。今天我想这事宜早不宜迟,于是早上找熟人订了票,2570RMB。把信息发给公司行政后就开始考虑怎么把钱拿到手了。结果等了半天没有回信,没办法,打电话过去催一下,行政也客气,说马上就帮我去办。结果等了半天,行政电话过来说代理公司觉得麻烦,所以决定直接把钱给我,明天让司机带过来。当时我就像骂人,我这几天可没少在公司问人,想转手那个破奖,直弄得别人见我就摇手。然后好不容易以一顿饭的代价找了同事的姐姐帮忙订了票,现在竟然说可以直接给我钱,TMD早点干嘛不说!!
我只能让同事的姐姐把票给取消了,虽然没有折钱,但也是一个人情了。遇到这样的公司我真的无语!
2008年1月22日星期二
Primeval Season2 Start
Primeval,中文名是远古入侵,这部片子是我前阵子无意中看到的,剧情老套,但是很合我的口味。另一方面英国英文听起来别有一番风味,英国式的幽默也和美国人的幽默不同,看多了美剧换换英剧也不错。
这部片子讲的是时空中出现了Anomaly,一种类似时间隧道的东西。远古生物可以通过这个东西来到现代社会,这个东西可能出现在任何地方,有霸王龙的森林,有15英尺长的远古巨鳄的湖泊,甚至还有超级进化捕猎生物的未来世界。每集讲一种生物通过Anomaly来到现代,然后英国的Home Office组成了一个team来处理这种情况。但片子不是那种重口味的恐怖片,里面到处充满了英国式的小幽默,我喜欢!
还有一条主线,就是主角,Cutter教授的妻子在8前年进入这种隧道,然后在现在世界和远古世界中流连忘返,她明明知道回来的途径,但是却不肯回来,然后又每每在众人危及的时候出现帮人一把,给人感觉是非常不可信任的一个人。但是她却有着比主角们多8年寻找和对付Anomaly的经验,使得主角们不得不依靠她的帮忙。
这个故事听起来很老套,但是时间和空间错位永远可以有无数吸引人的话题。而且巨型怪兽或者傻乎乎的渡渡鸟之类的东西,还是很吸引人的。特别是最后教授在过去做的事情竟然影响到了现实世界,使得现实世界的一个人一下子从人们的记忆当中消失了,而这个人却是教授在失去妻子8年之后重新爱上的一个女人,呵呵,事情有趣了。
现在,第二季终于出来了,回去下载!
对我来说不实惠的一等奖
今天特意去行政那里问了一等奖到底是怎么兑奖的。结果行政告诉我,要我先去订一张飞机票,然后通知公司行政,他们会去找代理商,如果价格超过2500,我需要先垫上差额,然后代理商才会打款给订票公司,然后让他们出票,把行程单给我送来。然后如果我要退票之类的自己再单独和订票公司办!
对于我这个想换现的人来说,这样的做法简直超级麻烦!唉,为什么我不是二等奖或者特等奖呢?
这句话是不是有点欠揍,不过,欠揍我也要说,因为我不爽!
2008年1月21日星期一
我中了一等奖!
真不敢相信,我竟然在公司年终联欢上面中了一个一等奖--价值2500RMB的机票一张。
公司这次竟然难得大方了一回,百来号人几乎人人有奖。首先50个普奖,价值100元-200元不等的奖品,然后25个高级点的普奖,价值200元-700元不等,三等奖3名,价值800元的三星移动硬盘一个。然后两个二等奖,PSP一个。一个一等奖和一个特等奖,价值5000多的液晶电视一台。
老实说,我一开始就在祈祷,因为我最想要的是PSP,所以我一直要老天保佑,不要让我抽到垃圾奖。抽完普奖我一下子心情激动起来,因为在还剩下20来个人里面抽三等奖,二等奖,一等奖和特等奖,概率是多么的高。但是抽完二等奖,看到PSP落入他人之手,我的心情又沮丧起来。因为我从小到大就没有中过任何奖,既然我一直期盼的PSP没有给我,那说明这次老天还是没有帮我。可是等到一等奖的电话号码出来,我一看最后四位是2007,我一下子傻了,没想到老天还是给我开了个玩笑,先让我沮丧一回,然后一下子给我一个惊喜。
不过老实说,这个奖实在不实惠,要我自己拿了机票去报销。我又不打算出去玩,这机票只能从别人那里拿了。
我现在正在考虑,这点钱该怎么用呢?买PSP好呢,还是买XB360?
2008年1月17日星期四
C++基础:重载与覆盖
今天,问了一个同事关于overloading和overriding的区别,但是这位已工作多年的程序员竟然支支吾吾说不清出其中的差别。这点我很吃惊。后来又问了几个人,发现竟然不止一个人没有搞清其中的差别。>
重载(overloading)和覆盖(overriding)其实是八竿子都打不着的两个概念。
重载指在同一个程序块范围中有多于一个函数用相同的函数名但是拥有不同的函数签名。
这句话里面有几个概念。一个是在同一个程序块范围(Scope)里面的才算重载。第二个就是函数签名。不同的函数签名指的是有不同的个数和类型的参数,函数签名不包括返回值。比如:
void foo(int& i);
int foo(int& i);
这两个函数拥有同样的签名,因此不算是重载,而且编译器会报错。
当提供了重载函数,在调用这个函数的时候,编译器会根据一定的规则(参数匹配,自动转换匹配等),来找到最合适的函数调用。重载的意义很重要,他提供了一种设计手段,使得相同的抽象概念接口可以根据实际情况(参数)来产生多种实现。比如最常用的是操作符重载。当一个自定义类型在语意上应该提供类似自然数的+操作的时候,它可以通过重载这个操作符来获得这种很自然的行为。
T t1,t2;
t1 = t1+t2; // overloading operator +
t1 = t1.Add(t2); // member function.
上面两种表达法中,很明显第一种更自然。
覆盖(overriding)指派生类(derived class) 提供了和基类(Base Class)中相同名字和签名的虚函数。那么这里也有两个概念。一个是覆盖仅发生在继承关系中,这和重载产生作用的范围不同。另外一个是覆盖只能针对于父类的虚函数,不是实函数也不是纯虚函数。看下面的代码
class Base{
public:
//....
virtual void foo(int);
void foo(double);
//....
}
class Derived{
public:
//...
void foo(int);
void foo(double);
//...
}
在这段代码中,基类Base中有两个函数,这两个函数是重载函数。在派生类中,第一个函数覆盖了基类中的虚函数。而后面一个foo(double)并不会覆盖基类中的同样签名的函数。因为在基类中那个函数不是虚函数。另外在派生类中的两个foo同样是重载函数。派生类中的foo(double)不会重载基类中的函数,因为他们在不同的scope中。
重载和覆盖的话题并不至于此,还有在template中的让人混淆的用法,但是千变不离其宗,记住这两个概念的作用域和发生的上下文即可进行判断。
2008年1月14日星期一
软件开发方法浅谈(三)
最近生了一场大病,浅谈的整理断了几天。我已经好几年没有生病了,没想到这次一下子来的这么猛。我整整吊了4天盐水,现在还没有恢复,但是班还是要上的,否则没钱看病了。现在自己觉得身体越来越差,希望和我一样做IT的朋友要注意自己身体了,每天至少要有半小时的锻炼,吃一些善存之类的维生素片,弥补饮食结构带来的隐患。好了,闲话不多说,继续。
浅谈(二)里面已经整理了一些需求获取的方法。那么这里就可以说说从需求到设计的过程了。软件设计是大家研究的最多的东西,至今为止有可以说无数中设计方法。从以前学校里面学的自上而下、模块化到现在主流的面向对象(OO)的设计方法。我现在主要使用模块化和OO这两种方法。前者用于设计小型的工具软件,后者用于设计公司的软件产品。但是从需求到设计的过渡,关注的人就少很多了。下面就仔细说说从需求到设计的过程,或者说--需求工程。因为据我的经验来说,这部分是最难的。Frederick Brooks在《没有银弹》中也充分说明了需求工程在软件项目中扮演的重要角色。这部分过了之后,再细分就是水到渠成的事情。就算小部分出错,也不会影响到系统全局。
1. 需求的层次
“最为困难的概念性工作便是编写出详细技术需求,这包括所有面向用户、面向机器和其它软件系统的接口”。这句话充分说明这个过渡阶段的重要性。
一般来说,需求有两种:用户需求和软件需求[1]。这两种分类也是两种层次。前者就是我在浅谈(二)中所指的从用户那里搜集过来经过简单加工的关于系统行为和反应的要求。用户需求往往包含着两个目的。
- 我要完成一项工作
- 这项工作的流程和结果要符合业务规则
- 功能性需求规定了系统要实现的功能,使得用户可以完成他们的工作,并且符合业务规则。
- 非功能性需求则指明了为了要使用户完成目标而需要满足的除了功能以外的要求。这些要求往往是涉及系统的性能、可靠性,安全性,可维护性等方面的要求。
2. 需求的粒度
需求获取到什么程度可以进行设计,这个度的把握不容易。如果无法获得足够的信息,就没法过渡到设计。如果要获得足够多的信息,时间却不允许。那么如何掌握这个度呢?我认为,能把用户的一个目标实现从输入到输出串得起来就可以了,也就是说得通,细节部分不用太关注,要关注得是搞清用户目标,以及现存的支持系统。
我相信实践出真知,检验知识也要靠实践,因此这里开始用一个贯穿全文的例子来说明如何精化需求的。
例子是这样的:我们刚刚获得了一个项目,这个项目是要为牛逼公司打造一个报表系统。首先从NB公司那里获得的需求。他们的要求很简单,“我们要一个报表系统,我们经理每天早上一上班就要看到报表打印出来放在他的办工桌上面。”。然后经过一连串的需求挖掘。我们整理出了初步的需求如下:
是的,听起来很简单,但是我们很快会发现一些问题。比如数据从哪里来、有哪些种类的数据等等。然后继续获取需求。然后我们扩充了这个需求(通过上一篇文章中的方法)。
牛逼公司的生产部经理牛魔王每天早上需要看报表。报表的内容是前一天公司生产车间所有设备的生产计划、实际生产结果、运行情况、维修明细、产量、故障情况、员工生产率和库存情况。
牛逼公司的生产部经理牛魔王每天早上需要看报表。报表的内容是前一天公司生产车间所有设备的生产计划、实际生产结果、运行情况、维修明细、产量、故障情况、员工生产率和库存情况。他要求每一种分类单独一张报表,然后把他们合起来打印成一张大报表(B3),使他能看得方便,快速。
数据来源于各个设备。设备每过一段时间会自动产生这段时间内的运行状况的数据。如果出现紧急问题,设备会直接发送事件。如果断线,设备在连接恢复之后自动上传断线期间的数据。
车间主任负责制定生产计划,核查实际生产结果,核对库存情况。他需要将这些数据记录下来,以备核查。
到了这个程度,所有的过程听起来似乎已经比较合理了。车间主任制定生产计划,然后工人使用设备进行生产。设备定时产生数据,我们只要获取这些数据,加上车间主任制定的计划,就可以自动产生报表。当然,把报表放到牛魔王经理的桌上这种工作还需要小秘玉面狐狸来做。
3.从需求过渡到设计
需求过渡到设计的最终目的就是完成可用的软件需求和设计。告诉开发人员该怎么开发,才能完成客户的要求。所以这一阶段需要和开发人员,测试人员进行讨论,一并决定如何设计。这在很多公司都不受到重视,甚至无视,这是一种完全错误的做法。这些公司的做法是由一个较为资深的人单独决定什么该做,什么不该做,该怎么做。听起来不错,但是实际上资深的人往往并不如表面上那么“资深”,他在做决定的时候往往对可行性,可测性考虑太少。说到底,资深的人考虑的是上层抽象,“资浅”的人考虑的是实现细节,两方面合起来,达到的效果才能最好。
实际的过渡方法有很多种,现在流行的是OO方法通过编写用例,转化为领域模型,然后设计E-R模型,然后用UML中的静态视图,活动视图,交互视图等方法来完成初步的设计。但是有一点要清楚,UML是工具,真正的产出是我们的设计思想。我们一步一步把需求转化为设计的思想才是我们真正要追求的。
这里是我自己以及和同事,同学讨论的一个简单的方法的总结。
第一步我们有了类似上面那段话一样的需求。这样的需求常常被称为场景(Scenario),或者有时候还不构成场景。但是最起码我们知道了要做一件什么事情。于是我们可以把用户做这件事情的步骤一步一步写下来,这就是所谓的用例(Use Case)。但是很多人常常犯一个错误,总是把UC写成软件规格说明,常常写系统第一步做什么,第二步做什么,最后输出什么等等。我到现在还会不由自主的犯这种错误。记住:用例和场景都是用户从系统外部使用系统的过程以及系统给出的反馈。所有用例的总和就是该系统需要完成的所有任务。
第二步我们需要把用例转化为软件规格说明,但是并不是一下子转过去的。在这里,有两种方法。第一种是首先把UC转化为粗粒度的领域模型,这时候领域模型中的各个元素都是系统的各个组件(物理或者逻辑),这些组件相互作用完成系统的所有任务。然后对各个组件的相互作用进行分析,设计出系统接口,也是功能需求,最后对各个组件内部进行细分,自上而下的分析,最后形成细粒度的软件设计。第二种则是在UC和场景的基础上,对软件进行全面的评估,然后写出特性列表(Feature List)。每个特性都由一到多个功能提供实现。然后对每个功能都写一个Func Spec描述这个功能的软件规格说明。
第三步,就是把软件规格说明变成软件详细设计。这一步的花样就很多了,可以用UML大展拳脚,也可以用传统的伪代码模块化实现,也可以把一个一个函数的实现写出来。反正这一部分对于程序员来说是最亲切的。
总得来说,需求分析中最复杂的还是第一步,这一步做好了,后面的事情就是按部就班,逐步细化。并没有太多的技巧。而需求分析却需要很多技巧和经验,需要想记者一样不停地挖掘客户的真正想法。
系列文章:
软件开发方法浅谈(一)--软件开发过程
软件开发方法浅谈(二)--需求工程之需求获取
[1] 有些分法是把需求分为业务需求,用户需求和软件需求三种。还有更甚者增加系统需求。但是在我看来,业务需求应该包括在用户需求里面。在真正做软件的时候,当然可以把一些很独立的,成体系的行业规范单独列出。但在需求工程中,这部分往往已经包含在用户需求之中。
2008年1月9日星期三
GFW bans tool of goolge
The GFW gets crazy again.
This time, it bans toolbar.google.com. But I think it bans a pattern of tool*.google.com.
I found this because I try to install google toolbar in my new laptop which loaded a new version of Ubuntu. I kept waiting the response of the page until I suddenly realize d that it is possibly baned.
I add the address to tor of firefox in my desktop computer. It works, it proved to be true that tool of google is baned.
What a stupid and presumputous GFW!
Is tool of google illegal? Is toolbar of google sensitively political?
The major product listed in tool.google.com is Google IME. Can we imply that this is a mean indirectly made by some local company who also want to publish their IME?
Well I don't know. What I can do is to harness tor.
If you don't know how to make use of tor to sufer internet freely, google it.
Thank god! google.com is not banned!
2008年1月3日星期四
软件开发方法浅谈(二)
上一篇文章浅谈(一)已经整理了我接触到的4种主要开发过程。这一篇文章就来仔细的整理一下软件开发中最重要的部分--需求获取和分析。
老实说,自己公司在这方面做的不是很好,大多数的实践方法是我从别的公司那里学来的,还有一些是自己看书和在网上与人讨论得来的知识。经过实践,祛除了一些我认为不是很好用的方法,改进了一些方法的实践步骤。
需求在很多人的眼里虽然重要,但是还是没有重要到能够和产出或者代码相提并论。但我觉得在整个开发环节中,需求是最重要的。我可以毫无疑问的说,需求是软件开发项目成功的首要条件。我们在开发过程中会遇到很多问题,比如最明显的就是不知道哪些要做,哪些不要做;做出东西之后客户不认可,性能没有达到要求,在部署之后客户发现软件和自己想要的完全不是一个东西等等,所有这些,都是没有搞清楚客户到底要什么所造成的。
那么,通过简单的询问就能得到客户的需求么?客户告诉你的就是他要的么?客户一天一个想法,哪个想法才是他真正想要的呢?这些问题不容易回答,我自己经验尚浅,但是经过了几个大型项目的锻炼,我也总结出一些粗糙的方法,这些方法在某种程度上可以解答这些问题。
1.从什么地方获取需求
首先可以从技术合同中获取需求。但是经验表明,那样的需求粒度太粗,只能用于提纲挈领,无法直接转换为软件需求。但是有了这些需求,就可以一条一条去确认,去核对,去细化。
通过和最终用户沟通获取需求。这里的最终用户一定要搞清楚,比如我们做地铁项目的,最终用户就是那些自动售票机的售票员,而不是地铁公司的领导。
通过和销售、售后人员沟通获得需求。对于产品项目,就会有销售,他们会告诉你客户想要什么,或者什么样的软件特性是卖点。售后人员会告诉你上一版的软件有什么问题,这一版需要改经等等。
通过分发试用版本获得需求。beta版的产品就可以分发给用户进行试用了。他们的反馈是非常珍贵的实际需求。
以上都是一些大分类,另外还有一些途径比如产品论坛,内部其他项目人员,技术支持等等。但是有些需求是会遗漏的,那就是来自自己老板的需求。这些需求大多和盈利指标挂钩,这些可是非常重要的。
2. 什么是真正的需求
“客户往往不知道自己要什么”,这句话一定要牢牢记住。一般来说,第一次和客户谈,他给出的信息都不是最终需求。为什么呢,因为他也没有经验,他没有使用过。所以他只能大概的说一些。而第一次,我们需要的也就是大概的东西。然后如果使用敏捷法,那就可以开始干活了,然后再让客户使用,获得正确的反馈。但是在一般开发过程下,我们需要做一些东西,比如原型系统、Storyboard等等,给用户一个能够使用的环境,让他切身体会一下。但是,一定要有场景。只有在某个通用的场景下面的试用活动才能挖出真正的需求。客户会兴致勃勃的把自己代入那个最终场景,然后你就能清清楚楚的知道他怎么来做的,他想怎么做。不要怕麻烦,这种方法绝对可以让你省去后面一大堆麻烦。
谈话的技巧很重要,我们时间有限,不能跟客户胡侃,必须要在有限的时间内尽量引导客户谈正题。因此在找客户谈之前,了解客户行业背景,做准备,列问题就很重要。实际上,这个时候我们就和一些谈话节目的主持人一样。因此对于需求分析工程师来说,学习行业知识远比技术知识重要得多。
尽量找行业经验丰富的客户了解需求。比如我们去一家公司为其定做一套软件,那我会找怎么样的人来了解需求呢?我不能直接跟对方客户说,我要找一个经验丰富的人。我会虚拟一类人,把他代入这个软件的使用者,给他尽量真实的生活经历和工作经历,然后向对方要最符合的一个人。
注意大量隐藏的需求。比如我们地铁行业,一条线路的客户只会考虑本线路的要求,但是多条线路会共同运营,乘客会换乘,我们就需要考虑一些客户没有考虑到的问题。另外比如我们观察到北京地铁使用自动售票机的最终用户都是年纪比较大的大妈,大婶级人物,那么一个隐藏的需求就是字体要大些,对比度高些,能让他们看得清楚。这些往往是生活常识,因此不太可能从别人嘴里得来,要靠自己的观察。
不要光靠自己。一个人的力量永远是渺小的。在获得需求的时候,可以使用头脑风暴之类的方法,让客户和己方不同人员共同参与,各抒己见,这样往往能获得很多需求,但是筛选也是个麻烦事。
并不是所有需求都接受!在谈需求之前,我们要记住项目的范畴,客户往往会认为自己是甲方,所以漫天开价,什么都想要,对于不在范畴里面的需求,可以拒绝。但有时候为了打开市场等目的,对于无理等要求也只能接受。对于有些需求,本身在范围之内,但是和开发与测试讨论后发现这个需求开发时间非常长,或者根本无法测试的,这些需求也要和客户商量修改。
3.怎么样确定需求
一个需求分析到什么程度能够算行。这是仁者见仁,智者见智的问题。但是一般来说,如果一个需求能够写出一个用例(use case),那么这个需求也差不多可以了。用例需要有进入条件,退出条件(结果)和核心价值。进入条件指这个case是怎么触发的。结果就是这个case是怎么结束的,这两个都很好理解。那么核心价值是什么?核心价值是指该用例满足了用户哪个明确的需求。
需求就是我们要开发的东西。这个开发涉及到很多人,不光是需求分析人员的事情。很多公司上层人员获得需求,但是却不让开发和测试人员知道,这些上层人员以为自己同意就行了,这种做法是错误的。因为真正开发的人是开发和测试人员,只有他们认可的、知道的需求才有意义。当然,上层人员可以命令他们做,但是告诉别人怎么做和自己知道怎么做,要做什么将会产生完全不同的结果。因此,在需求定下来之前,要一条一条获得开发与测试人员的同意。每个需求要和开发、测试人员要提出对这条需求的看法,是否能开发,是否可测等等。对于不能开发或者不能测试的需求,一律拒绝或者修改。一旦同意,则他们就要签字,这样也能形成连带责任。
需求的获取也有迭代,一开始的几次迭代只要把一部分核心功能的需求搞清楚即可,对于这部分的需求描述,粒度要细;而对于后面几次迭代的需求只要大致知道有这几个需求即可。那么,粒度要细到什么程度呢?简单的说,一个需求一个用例,一个到多个用例合起来形成一个用户场景即可。在写用例的时候,不涉及任何技术或者系统内部的表现,只有系统外部的表现和给用户的反馈。
比如说,用户在线买本书。用户看到了一本要买的书,然后点击加入购物车,然后去网上支付,完成交易。这是一个完整的场景,而核心价值就是用户买到了书。因此无须写多个用例。一个用例即可。同时在用例里面加入可能的分支情节,比如用户未登录等等。
再举个例子,用户进入地铁站。那用户首先要去买票,他可以在自动售票机那里买,也可以在人工售票机那里买。然后他在闸机那里刷卡进入车站。那这种情况下,就是一个场景多个用例了。买票是就有两个用例,然后进站整个是一个用例。两个买票的用例从属与进站这个用例。但是对于客户来说,因为他最终目的是为了进站,所以买到票在进站是一个完整的需求。
总结一下,需求分析的目的就是要获得客户真正想要的东西,也是我们能够真正开发的要求。很多项目的失败都是因为没有搞清楚这点。做出来的东西和别人要的不一样,别人当然不肯给钱。然后再进行修改,变更,成本也随之上升。千里之行,始于脚下。眼睛不要看得太远,而忽略了身边的事情。
2008年1月2日星期三
软件开发方法浅谈(一)
很久没用中文写文章了,这篇就用中文吧。
做事情要有方法论指导,否则就是瞎做,乱做。在软件行业,有着别其他行业更多的方法论。在过去的几年中,我接触了一些,实践了一些,对各种软件开发方法有了一定的了解。正值岁末,我就来简单地整理一下,首先说说软件开发过程。
首先了解一下概念,一个软件的开发要经过的一系列的环节,一般的开发主要包括分析,设计,编码,测试和发布(或部署)这几个环节,在这个行业的人都知道。但是如何区分这几个环节呢?这几个环节每个环节的输入是什么?输出是什么?
为了回答这些问题,人们开始制定一些标准或准则,用来规定各个环节的工作以及产出。毕竟,一个软件的开发是为了赚钱,如果没有产出,如何赚钱呢?这种标准就是软件工程中说的软件开发过程。也有人称之为软件生民周期。但是这两个概念还是有所不同。前者着重一个东西从无到有的过程,后者着重时间的发展。但我这里还是把两个概念并成一个,主要介绍过程,因为过程也包括了时间的发展。
很显然的,这个过程设计的好坏会直接影响到东西的质量,更会影响到这个东西能带来的利益好坏。因此,很早以前,国外很多公司就成立了QA部门,定义一些自己的过程来确保质量。有一些过程名声显赫,最终成为了一个时代的标准。
1. 瀑布模型(Waterfall Model)
这个名字软件行业的人耳熟能详,但现在已经成为了贬义词。如果你公司使用瀑布模型,估计会遭人白眼。为什么,因为使用瀑布模型而失败的项目不计其数。但是,要知道,这是第一个把软件生命周期明确定义出来的模型,现在的很多开发过程,只不过是把这几个阶段拆分,打散,拉长,缩短来适应需求而已。再把眼睛往后看30年,那个时候的软件远远没有这么复杂,需求简单而明确,因此瀑布模型还是很适合的。但是,现在的世界发展太快,人类的知识面和想像力都无限膨胀,对软件开发商的要求越来越多了,很好,这才是真正的产业。因此瀑布模型的缺点就出来了---简单的说,就是不能应付需求变更,或者更准确地说,应付需求变更的成本太大。瀑布模型中要求需求全部弄清楚之后才开始设计和开发,但是现在的软件大多数规模庞大,跨地域工作又提高了沟通成本,导致需求很难在一开始就全部弄清楚,但是时间不等人啊,根据瀑布模型就开始工作,到了后期,需求变更对于已经设计差不多完成的软件来说无疑是个灾难。很自然的,人们开始想到螺旋模型。
2. 螺旋模型(Spiral Model)
这个模型很简单,就是把一个大的瀑布模型拆分成多个小的瀑布模型。这很符合需求导向的软件开发实际情况。比如一开始掌握了20%左右的关键需求就开始了第一个瀑布模型,完成这个阶段之后再开始后面的20%或者30%需求。很明显,这样提高了质量,减少了需求变更的成本。而且在每个阶段也不需要投入非常多的人力了。试想一下,原本三个月做100%需求可能需要6个人,现在1个月做20%的需求可能只要1个人了。这是多大的节省啊。老板们开始期待软件项目的成功了。可是,他们很无奈的发现,螺旋模型也有缺点--每个周期结束没有明确的输出,这可能导致后面的周期无法正常开始,最后的集成往往产生很大问题。往往螺旋模型一开始很顺利,到后面越来越难转下去,就想一个陀螺一样。我一开始就说过,开发过程是一些准则和标准。因此,人们决定要把螺旋模型改造一下,定义其开始标志和结束标志(输入和输出)。于是,迭代模型产生了。
3. 迭代模型(Iteration Model)
迭代模型是一个很有意义的进步,他每个阶段的设计都非常灵活。通常来说,每个公司都有自己的迭代模型,但是有一点不会变,就是迭代模型明确规定了各个阶段的开始标志,输入条件,输出内容和结束标志。当然,其中最重要的还是输入的内容和结束标志。每个阶段的结束都称为Milestone。迭代是很灵活的,对于小规模的开发,迭代是线性的,也就是一个迭代完成再进入下一个迭代。而对于大规模开发,可能就是并行的。各个子系统并行迭代,每个子系统内部再进行线性迭代。
然后每个迭代也不能就这么叫迭代了。对于一个软件项目,总归会有需求分析阶段,设计阶段,开发阶段,验证阶段和发布阶段。这些阶段都不是纯粹的做单一的工作,比如需求分析阶段,不是单纯的做需求分析,也有一些少量的开发,同时一些测试用例也开始设计起来。但是这个阶段主要还是做需求分析,因此就叫做需求分析阶段。类似的,开发阶段的主要工作还是开发,但是也有一定量的需求分析工作。简单的说,就是谁占主导地位,就叫谁的名。对于阶段的名称,每个公司都不同,每种开发过程也都不同,不用去特别的记忆,因为背后做的事情就是这些。但是对于大的项目,往往每个大阶段里面还有小的迭代。比如一个需求分析阶段就会有1~2个迭代,开发有2~3个迭代等等。这要根据实际情况来。
那么每个迭代干什么事情呢?其实每个迭代也犹如一个小的软件生命周期,基本上都包括了需求分析,开发,测试等阶段。但是每个阶段时间很短。因为实践证明,一个迭代不要超过4~6周,因此在开发阶段往往是2~3天分析这个迭代要做的事情,1~2周进行开发,1周进行测试,然后几天进行发布。但是再需求分析阶段,需求才是最重要的事情。因此在该阶段的迭代的特征是需求往往占据80%以上的迭代时间,剩下的是一些原型开发,不带测试和发布的迭代。
迭代的内容和内部时间比例是灵活的。但是输出却是固定的。在设计迭代的时候就已经定义好,每个迭代的输出是什么。这个标准在很多公司被称为迭代的退出条件(Exit Criteria)。达到这个条件,迭代就可以退出,向下面一个前进。比如在需求阶段,第一个迭代做了20%的需求分析,这些需求就是要在后面一个迭代进行开发的内容,因此这个迭代的输出就是需求分析文档和这部分的设计文档。需求文档需要非常详细,每个测试人员和开发人员要清楚的知道自己那部分的需求是什么。设计文档中软件规格说明书一般由PM编写,不涉及具体的技术细节,是用户需求到软件需求的一个转化。这部分也需要很详细。设计文档还包括SE编写的软件设计文档(系统架构,数据库设计,接口设计,类图,事件流程等),但是可以是一个初步的第一版的设计。如在开发阶段,那每个迭代的主要输出就是程序了。
刚接触迭代开发的人会觉得很简单,但是真正做了之后就发现根本无法估量后面的工作量。甚至后面的几个Milestone都无法确定时间,这真是件头疼的事情。事实上,这却是很难。在现实生活中,有这几种情况。一、项目是时间点驱动的。比如某某时间会开一个软件大会,某某时间是娱乐,游戏软件的黄金上市时间,某某时间是行业大会等等。这种情况下,时间就是确定的了。所要做的就是把这些时间里面能够完成的功能做出来。二、项目是有固定截至时间的,无论是合同规定还是成本要求都使这种情况最普遍。这种情况下面,首先把几个大的阶段分出来。只要粗略地分一下即可。但是对于需求分析阶段,却需要仔细的分配时间。因为往往需求阶段只有一个迭代。后面就直接进入设计阶段了。因为需求分析的这个迭代和设计阶段的第一个迭代需要在一开始就定义清楚退出条件的。这个阶段的需求包括系统总体的需求和一部分地层的,关键的需求。因此需要对所有的需求分优先级,然后完成一部分最高的。估算迭代的具体方法会在后续文章中详细介绍,这里就说一个宗旨,估算迭代只要估算清楚当前的和后面的一到两个即可。
有些公司在迭代模型的基础上,详细的定义了每个阶段的输出,并且附带实行的方法,可称之为一套完整的方法论,其代表就是RUP(Rational统一过程)和MSF(微软解决方案框架)。RUP把原先上面我说的一维阶段--需求,设计,开发等变成了两维的--时间和内容。时间分为初始、细化、构造和交付;内容则用工作流定义分为建模、需求、设计、实现、测试和部署这几个核心工作流和配置管理、变更管理、项目管理和环境这几个支持工作流。每个时间阶段里面都有一到多个迭代,每个迭代中都有不同的工作流,每个工作流的制品输出也不同。每个工作在不同时间的不同迭代里面占的比重不同。看下其概念图,很容易理解。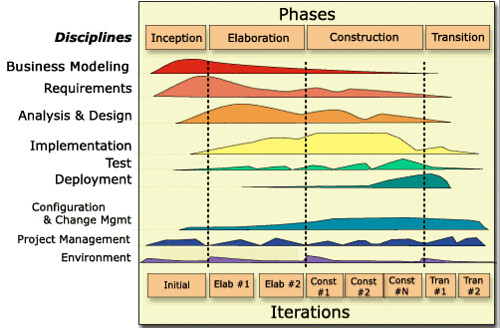
MSF的体系很复杂,包含了开发过程,团队合作,技术体系等一系列内容。这里不考虑其他的东西,仅仅考虑其开发过程。MS的开发过程分为planning, initialization,implementation,stabulization和release这几个阶段。其实这样的分法更科学。第一个是计划(planning)而不是需求更表明了他们在迭代开发时候的灵活性。这两套体系都是他们根据各自的多年经验积累而成的,但是选择使用却要符合自己公司的现状,不能照搬照套。
4. 敏捷开发(Agile)
敏捷开发严格来说不是一种开发模型,也不是一种严格的生命周期模型。我更倾向于称它为一种理念。敏捷开发门派众多,我所知,所用也是有限,因此就拣这些我接触过的来整理比较好。说它是理念,因为敏捷开发实际上仍然逃不出需求,设计,开发,测试和发布这几个基本元素。它只是把这些元素的具体实践方法做了一些改动,使其适应性更强,灵活性更高,交互性更好,时效性更强。比如XP(eXtremeProgramming),有12种实践方法用来提高各个阶段的输出质量。它提倡的是快速开发,做出可交付的产品,交由客户使用,获得反馈,然后继续下一轮迭代。但是注意,它不是随便做做,我们以前做原型都是报着可作可不坐的心态,但是XP提倡的是“可交付的产品”,这句话保证了其质量品级。XP提倡TDD(Test Driven Development)测试驱动开发也是一个非常有用的实践。通过写测试用例,程序员很清楚这个功能的需求是什么,要达到什么目标才算通过,有目标的行为,当然效率要高些。Scrum有15min standing meeting,提倡开会少而精,每天跟踪进度,让每个人清楚三件事情:昨天已经做好什么,今天要做什么,现在有什么问题!
敏捷开发现在正在慢慢被人接受,别人认可。但是在真正的应用上,我个人认为还是应该先练习“楷书”--传统过程,再学习“草书”--敏捷开发。这样才能以不变应万变,特别是对年轻的没有经验的团队。君不见发明Agile的都是那些大胡子秃顶的老头么?他们的经验何其丰富,草书再草也不会失去控制变成涂鸦。
总结一下,软件开发方法很多,但是经典的就这么几种。重要的不是方法本身,而是知道在什么时候使用什么方法。比如自己做个习作,就一两个月的时间,需求明确,那用瀑布模型是最省力省心的。总之两句话: Do right things! Do things right!
订阅:
博文 (Atom)

